
Rearrangement Challenge 2022
Held in conjunction with the CVPR 2022 Embodied AI Workshop
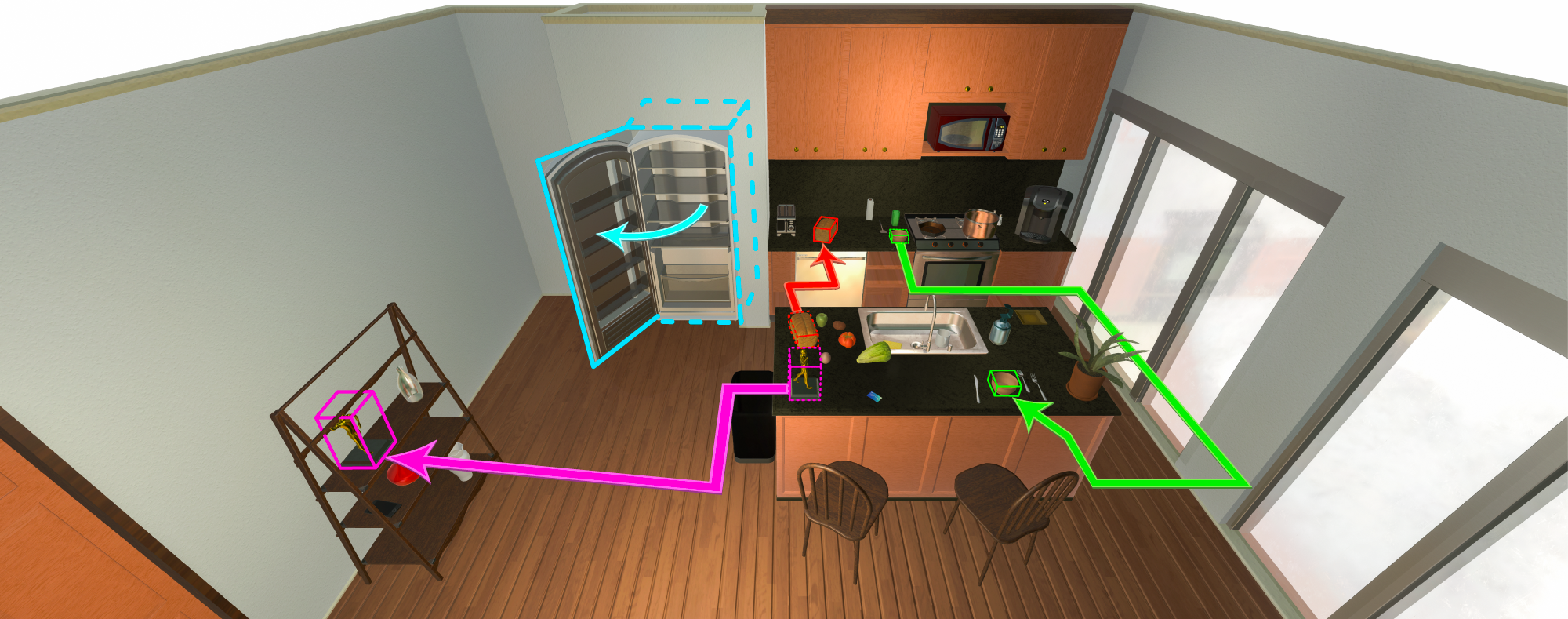
Welcome to the 2022 AI2-THOR Rearrangement Challenge hosted at the CVPR 2022 Embodied AI Workshop. The goal of this challenge is to build a model/agent that moves objects in a room, such that they are restored to a given initial configuration.

Our rearrangement task involves moving and modifying (i.e. opening/closing) randomly placed objects within a room to obtain a goal configuration. There are 2 phases:
- Walkthrough. The agent walks around the room and observes the objects in their ideal goal state.
- Unshuffle. After the walkthrough phase, we randomly change between 1 to 5 objects in the room. The agent's goal is to identify which objects have changed and reset those objects to their state from the walkthrough phase. Changes to an object's state may include changes to its position, orientation, or openness.
For the 2022 challenge, we have two distinct tracks:
- 1-Phase Track (Easier). In this track we merge both of the above phases into a single phase. At every step the agent obtains observations from the walkthrough (goal) state as well as the shuffled state. This allows the agent to directly compare aligned images from the two world-states and thus makes it much easier to determine if an object is, or is not, in its goal pose.
- 2-Phase Track (Harder). In this track, the walkthrough and unshuffle phases occur sequentially and so, once in the unshuffle phase, the agent no longer has any access to the walkthrough state except through any memory it has saved.
In both of these tracks, agents should make decisions based off of egocentric sensor readings. The types of sensors allowed/provided for this challenge include:

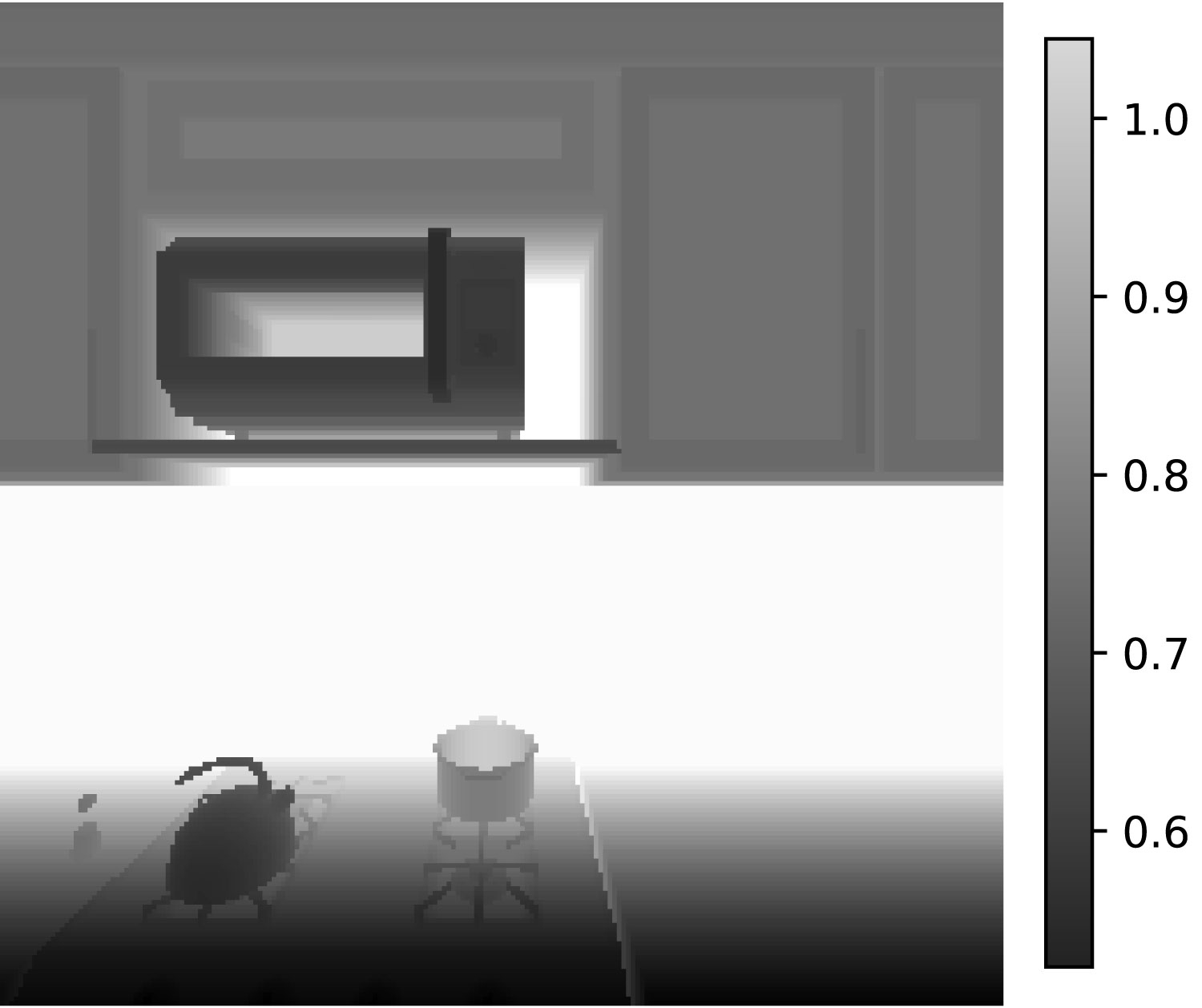
- RGB Images - having shape 224x224x3 and an FOV of 90 degrees.
- Depth Maps - having shape 224x224 and an FOV of 90 degrees.
- Perfect egomotion - We allow for agents to know precisely how far (and in which direction) they have moved as well as how many degrees they have rotated.
While you are absolutely free to use any sensor information you would like during training (e.g. pretraining your CNN using semantic segmentations from AI2-THOR or using a scene graph to compute expert actions for imitation learning) such additional sensor information should not be used at inference time.
A total of 82 actions are available to our agents, these include:
Navigation
- Move[Ahead/Left/Right/Back] - Results in the agent moving 0.25m in the specified direction if doing so would not result in the agent colliding with something.
- Rotate[Right/Left] - Results in the agent rotating 90 degrees clockwise (if Right) or counterclockwise (if Left). This action may fail if the agent is holding an object and rotating would cause the object to collide.
- Look[Up/Down] - Results in the agent raising or lowering its camera angle by 30 degrees (up to a max of 60 degrees below horizontal and 30 degrees above horizontal).
Object Interaction
- Pickup[OBJECT_TYPE] - Where OBJECT_TYPE is one of the 62 pickupable object types, see constants.py. This action results in the agent picking up a visible object of type OBJECT_TYPE if: (a) the agent is not already holding an object, (b) the agent is close enough to the object (within 1.5m), and picking up the object would not result in it colliding with objects in front of the agent. If there are multiple objects of type OBJECT_TYPE then one is chosen at random.
- Open[OBJECT_TYPE] - Where OBJECT_TYPE is one of the 10 opennable object types that are not also pickupable, see constants.py. If an object whose openness is different from the openness in the goal state is visible and within 1.5m of the agent, this object's openness is changed to its value in the goal state.
- PlaceObject - Results in the agent dropping its held object. If the held object's goal state is visible and within 1.5m of the agent, it is placed into that goal state. Otherwise, a heuristic is used to place the object on a nearby surface.
Done action
- Done - Results in the walkthrough or unshuffle phase immediately terminating.
Winners of the challenge will have the opportunity to present their work at the CVPR 2022 Embodied AI Workshop.
We have built support for this challenge into the AllenAct framework. For more information see here.
We are using the AI2 Leaderboard to host challenge submissions.
To make submissions for the 1-Phase Track of the rearrangement task, use the following leaderboard:
To make submissions for the 2-Phase Track of the rearrangement task, use the following leaderboard:
To cite this work, please cite our paper:

@InProceedings{RoomR,
author = {Luca Weihs and Matt Deitke and Aniruddha Kembhavi and Roozbeh Mottaghi},
title = {Visual Room Rearrangement},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021}
}


